 Rによるデータ分析 |
Excelによるヒートマップ |
Pythonによるヒートマップ
Rによるデータ分析 |
Excelによるヒートマップ |
Pythonによるヒートマップ
Rによるデータ分析 |
Excelによるヒートマップ |
Pythonによるヒートマップ
Rによるデータ分析 |
Excelによるヒートマップ |
Pythonによるヒートマップ
テーブルデータ全体の可視化 の一種です。 表形式のデータの表そのものをよく見ると、データの全体像や、データの背景がよくわかることがあります。
すぐにできるのは、データの文字を「読む」というやり方です。 しかし、この方法だと、データが大きくなった時に限界になってきます。 まず、表が画面に収まらなくなって来ます。 また、読み切れないですし、読んだ内容を理解仕切れないです。
ヒートマップ は、表形式のデータを「見る」というやり方になります。 ヒートマップを使うと、「読む」の弱点がかなり改善して、かなり大きな表でも、全体像が簡単に理解できることもあります。
Rのヒートマップのライブラリーでは、単に表を色したヒートマップを作るだけでなく、 クラスター分析 をして、データを並び方を変えることで、知りたいことに到達しやすくする方法もついています。 下記では、その他の前処理の方法もいれています。
例えば、1列目(一番左の列)がサンプル名になっているデータの場合、その列を指定すると、サンプル名がヒートマップの縦の列の名前になります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T, row.names=1) # データの読み込み。1列目をサンプル名として指定
サンプル名を指定しないと、すべての列がヒートマップで色を付ける対象になります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データの読み込み
ヒートマップは、数字に対して、色を付けるので、質的変数がある場合、前処理をする必要があります。
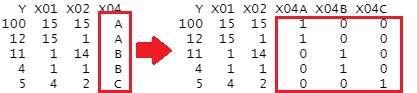
ダミー変換 をすると、それぞれの質的変数について、カテゴリの数の分、新しい列ができて、0と1の数字が入って来ます。
library(dummies)
Data <- dummy.data.frame(Data) # ダミー変換
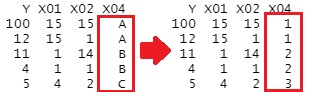
ファクターにすると、それぞれのカテゴリに数字が連番で割り当てられます。 ダミー変換と違って、列が増えないのが便利です。
Data2 <- Data
n <- ncol(Data) # 列数を数える
for (i in 1:n) {
if(class(Data[,i]) == "character"){ # 質的変数の列かどうかを判断
Data[,i] <- as.numeric(as.factor(Data[,i])) # ファクターに変換
}
}
正規化 すると、数字の表れ方の違いが見やすくなることがあります。
n <- ncol(Data)
for (i in 1:n) {
Data[,i] <- (Data[,i]-min(Data[,i]))/(max(Data[,i])-min(Data[,i]))
}
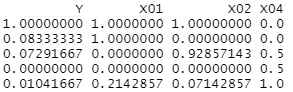
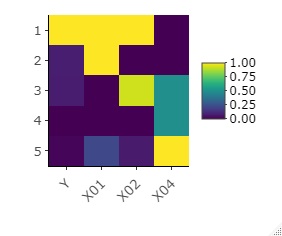
この例は、上記でファクターにした後に、データを正規化したものです。
特定の列について、数字の大きさの順番に並び変えると、似ている列が見やすくなることがあります。
Data <- Data[order(Data[,1], decreasing=T),] # 1列目を基準にする場合
heatmaplyを使うと、部分的な拡大もできるようになります。
列にクラスター分析をした場合、サンプルは近いもの同士でかたまるため、上記で並び変えをしていても無効になります。
library(heatmaply)
heatmaply(Data, Colv = NA, Rowv = NA)
library(heatmaply)
heatmaply(Data)
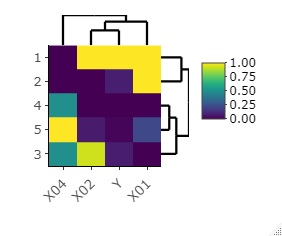
library(heatmaply)
heatmaply(Data, Colv = NA)
library(heatmaply)
heatmaply(Data, Rowv = NA)
library(dummies) # ライブラリを読み込み
library(heatmaply) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data2 <- dummy.data.frame(Data)# 質的変数はダミー変換
heatmaply(Data2, Colv = NA, Rowv = NA) # ヒートマップを作成

各変数で、平均0、標準偏差1に 標準化 してから、グラフにします。 値が大きく異なる変数が入っている時に、それぞれの変数の様子がよく見えるようになります。
library(dummies) # ライブラリを読み込み
library(heatmaply) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data2 <- dummy.data.frame(Data)# 質的変数はダミー変換
heatmaply(scale(Data2), Colv = NA, Rowv = NA) # ヒートマップを作成

各変数で、最小値0、最大値1に正規化してから、グラフにします。 効果は標準化と似ています。 質的変数が混ざっている場合は、こちらの方が0と1の出方が見やすいです。
library(dummies) # ライブラリを読み込み
library(heatmaply) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data2 <- dummy.data.frame(Data)# 質的変数はダミー変換
heatmaply(normalize(Data2), Colv = NA, Rowv = NA) # ヒートマップを作成

